优化第一步,创建高性能索引
索引基础
索引可以包含一个或多个列的值,如果索引包含多个列,那么列的顺序也十分重要,因为MySQL只能高效地使用索引的最左前缀列。
ORM工具能够产生符合逻辑的、合法的查询,除非只是生成非常基本的查询,否则它很难生成适合索引的查询。
在MySQL中,索引是在存储引擎层而不是服务器层实现的,所以,并没有统一的索引标准:不同存储引擎的索引的工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。
B-Tree意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同,能够加快访问数据的速度,从索引的根节点开始进行搜索,适用于全键值、键值范围或键前缀查找。
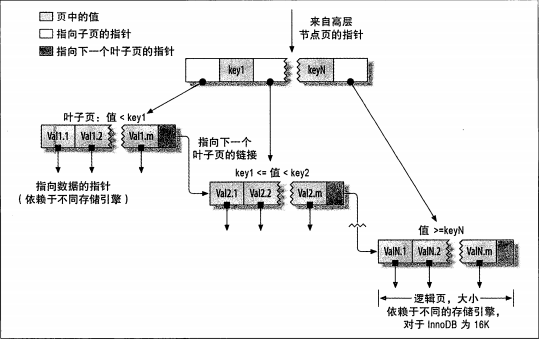
B-Tree索引的限制:
- 如果不是按照索引的最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效,只有Memory引擎显式支持哈希索引。
哈希索引的限制:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的
- 只支持等值比较查询,不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突
- 如果哈希冲突很多的话,一些索引维护操作的代价也会很高
空间数据索引(R-Tree),MyISAM表支持空间索引,可以用作地理数据存储,开源数据库系统中对GIS的解决方案做得比较好的是PostgreSQL的PostGIS。
全文索引,适用于MATCH AGAINST操作,而不是普通的WHERE条件操作。
索引优点
- 三个优点:
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O
- 索引三星系统:
- 索引将相关的记录放到一起则获得一星
- 如果索引中的数据顺序和查找中的排序一致则获得二星
- 如果索引中的列包含了查询中需要的全部列则获得三星
高性能索引策略
- 独立的列:如果查询中的列不是独立的,则MySQL不会使用索引。“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数
- 前缀索引和索引选择性:
- 通常可以索引开始的部分字符,可以大大节约索引空间,但也会降低索引的选择性
- 索引的选择性是指,不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间,选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行
- MySQL无法使用前缀索引做ORDERY BY和GROUP BY,也无法做覆盖扫描
- 选择合适的索引列顺序:
- 正确的索引列顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要
- 在一个多列B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列
- 将选择性最高的列放到索引最前列
- 聚簇索引(并不是一种单独的索引类型,而是一种数据存储方式)
- 最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于I/O密集型的应用
- 覆盖索引:如果一个索引包含(或者说覆盖)所有需要查询的字段的值,就称为覆盖索引
- 覆盖索引必须要存储索引列的值
- 如果EXPLAIN出来的type列的值为“index”,则说明MySQL使用了索引扫描来做排序
- 压缩(前缀)索引,默认只压缩字符串,减少索引大小,对于CPU密集型应用,因为扫描需要随机查找,压缩索引在MyISAM上要慢好几倍
- 重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引,应该避免这样创建重复索引
- 索引可以让查询锁定更少的行
维护索引和表
- CHECK TABLE检查表是否损坏,ALTER TABLE innodb_tb1 ENGINE=INNODB;修复表
- records_in_range()通过向存储引擎传入两个边界值获取在这个范围大概有多少条记录,对于innodb不精确
- info()返回各种类型的数据,包括索引的基数
- 可以使用SHOW INDEX FROM命令来查看索引的基数
- B-Tree索引可能会碎片化,这会降低查询的效率