MySQL的四种事务隔离级别
为什么要有事务?
事务广泛的运用于订单系统、银行系统等多种场景。如果有以下一个场景:A用户和B用户是银行的储户。现在A要给B转账500元。那么需要做以下几件事:
- 检查A的账户余额>500元;
- A账户扣除500元;
- B账户增加500元;
正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后,系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。
以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此。
事务是什么?
与其给事务定义,不如说一说事务的特性。众所周知,事务需要满足ACID四个特性:
- 原子性 (atomicity):一个事务的执行被视为一个不可分割的最小单元。事务里面的操作,要么全部成功执行,要么全部失败回滚,不可以只执行其中的一部分。
- 一致性 (consistency):数据库总是从一个一致性的状态转换到另外一个一致性的状态。如果上述例子中第2个操作执行后系统崩溃,保证A和B的金钱总计是不会变的。
- 隔离性 (isolation):通常来说,事务之间的行为不应该互相影响。然而实际情况中,事务相互影响的程度受到隔离级别的影响,文章后面会详述。
- 持久性 (durability):事务提交之后,需要将提交的事务持久化到磁盘,即使系统崩溃,提交的数据也不应该丢失。
事务的并发问题
事务的并发会带来几个问题:
- 脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
- 不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
注意,不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
事务的四种隔离级别
事务的隔离性受到隔离级别的影响,那么事务的隔离级别是什么呢?事务的隔离级别可以认为是事务的”自私”程度,它定义了事务之间的可见性。隔离级别分为以下几种:
- 读未提交(read-uncommitted):事务A对数据做的修改,即使没有提交,对于事务B来说也是可见的,这种问题叫脏读。这是隔离程度较低的一种隔离级别,在实际运用中会引起很多问题,因此一般不常用。
- 不可重复读(read-committed):大多数数据库系统的默认隔离级别,一个事务开始时,只能“看见”已经提交的事务所做的修改,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。
- 可重复读(repeatable-read):当某个事务在读取某个范围内的值的时候,另外一个事务在这个范围内插入了新记录,那么之前的事务再次读取这个范围的值,会读取到新插入的数据。Mysql默认的隔离级别是RR,然而mysql的innoDB引擎间隙锁成功解决了幻读的问题。
- 可串行化(serializable):最高级别,通过强制事务串行执行,避免了幻读问题,会在读取的每一行数据上都加锁,可能导致大量的超时和锁争用的问题。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 可串行化(serializable) | 否 | 否 | 否 |
为了帮助理解四种隔离级别,这里举个例子。
如下图,事务A和事务B先后开启,并对数据1进行多次更新。四个小人在不同的时刻开启事务,可能看到数据1的哪些值呢?
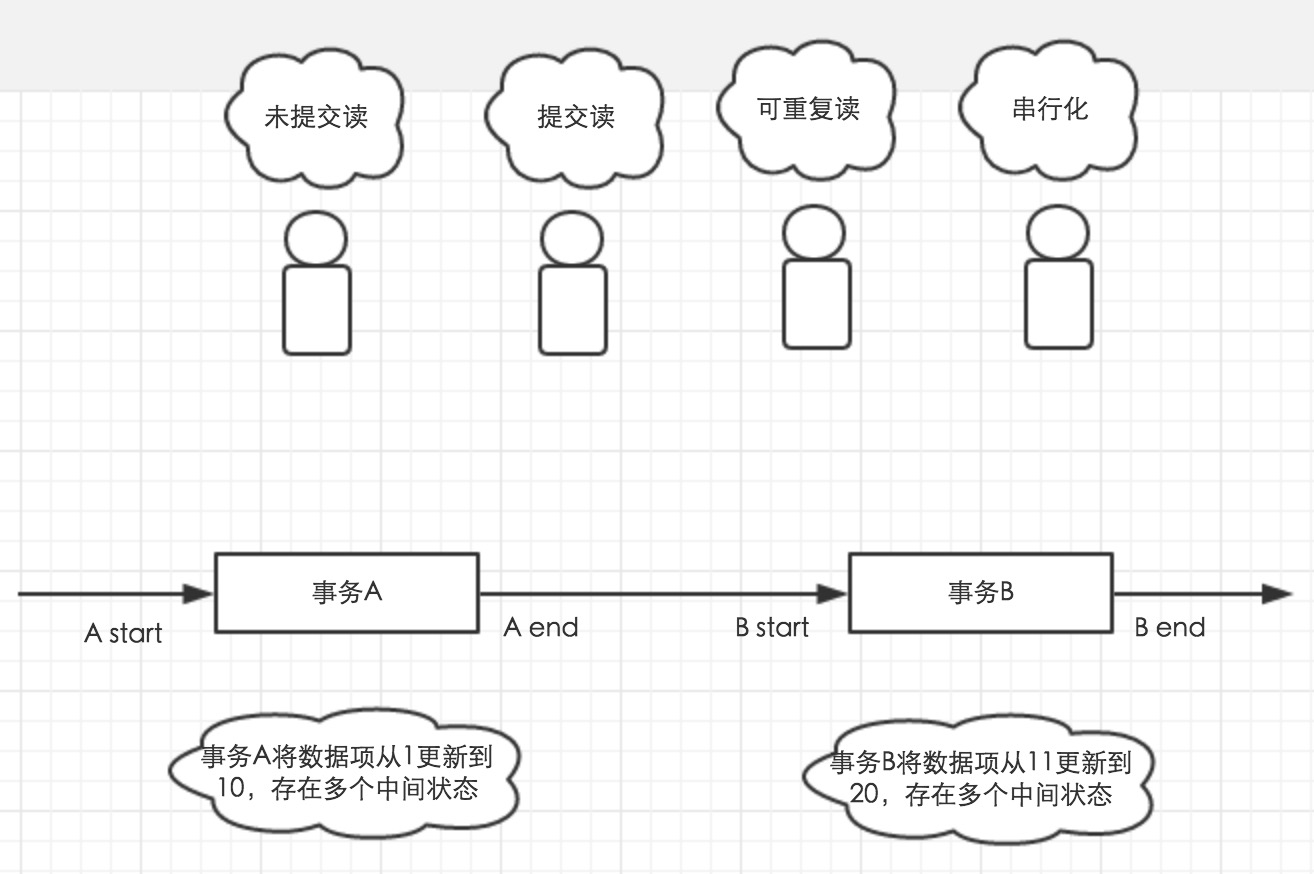
- 第一个小人,可能读到1-20之间的任何一个。因为未提交读的隔离级别下,其他事务对数据的修改也是对当前事务可见的。
- 第二个小人,可能读到1,10和20,他只能读到其他事务已经提交了的数据。
- 第三个小人,读到的数据去决于自身事务开启的时间点。在事务开启时,读到的是多少,那么在事务提交之前读到的值就是多少。
- 第四个小人,只有在A end 到B start之间开启,才有可能读到数据,而在事务A和事务B执行的期间是读不到数据的。因为第四小人读数据是需要加锁的,事务A和B执行期间,会占用数据的写锁,导致第四个小人等待锁。
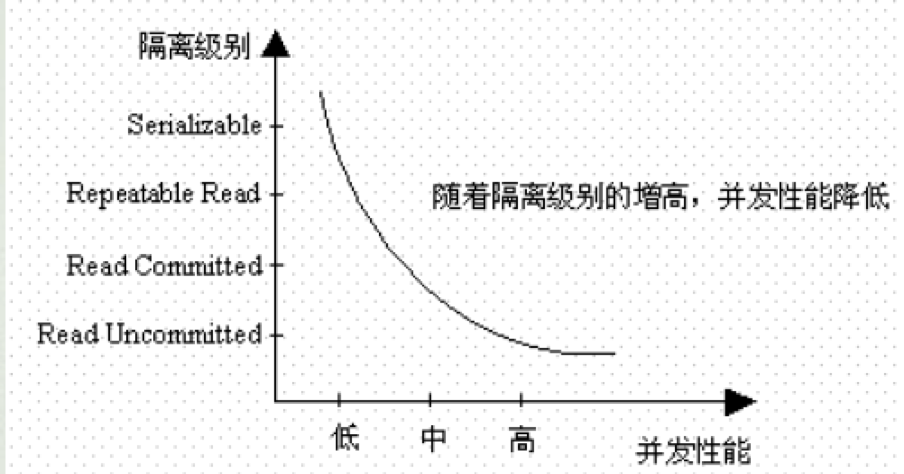
很显然,隔离级别越高,它所带来的资源消耗也就越大(锁),因此它的并发性能越低。准确的说,在可串行化的隔离级别下,是没有并发的。
MySQL中的事务
事务的实现是基于数据库的存储引擎。不同的存储引擎对事务的支持程度不一样。mysql中支持事务的存储引擎有innoDB和NDB。innoDB是mysql默认的存储引擎,默认的隔离级别是RR,并且在RR的隔离级别下更进一步,通过多版本并发控制(MVCC,Multiversion Concurrency Control )解决不可重复读问题,加上间隙锁(也就是并发控制)解决幻读问题。因此innoDB的RR隔离级别其实实现了串行化级别的效果,而且保留了比较好的并发性能。
事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。
redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。
事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘。
当事务提交之后,在Buffer Pool(Innodb维护了一个缓存区域叫做Buffer Pool,用来缓存数据和索引在内存中)中映射的数据才会在后台慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
- 记录1:<trx1, insert…>
- 记录2:<trx2, delete…>
- 记录3:<trx3, update…>
- 记录4:<trx1, update…>
- 记录5:<trx3, insert…>
undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程:
假设有2个数值,分别为A和B,值为1,2
- start transaction;
- 记录 A=1 到undo log;
- update A = 3;
- 记录 A=3 到redo log;
- 记录 B=2 到undo log;
- update B = 4;
- 记录B = 4 到redo log;
- 将redo log刷新到磁盘
- commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
分布式事务
分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。
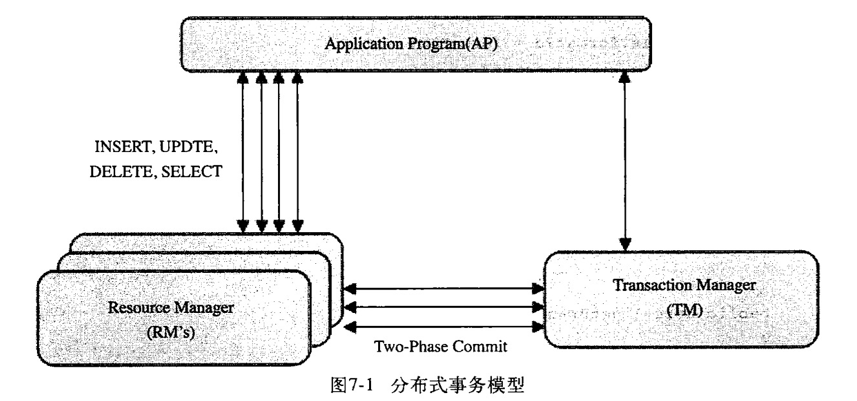
如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM)。
- 应用程序定义了事务的边界,指定需要做哪些事务;
- 资源管理器提供了访问事务的方法,通常一个数据库就是一个资源管理器;
- 事务管理器协调参与了全局事务中的各个事务。
分布式事务采用两段式提交(two-phase commit)的方式。第一阶段所有的事务节点开始准备,告诉事务管理器ready。第二阶段事务管理器告诉每个节点是commit还是rollback。如果有一个节点失败,就需要全局的节点全部rollback,以此保障事务的原子性。